
In the world of Large Language Models (LLMs), we often talk about “Pre-training” as the heavy lifter. It’s where models learn the fundamental semantics: coding rules, grammar, and complex concepts. But as the market matures, the real battleground has shifted to Fine-tuning.
If pre-training builds the muscle, fine-tuning is the specialized training that teaches that muscle how to perform a specific task, whether it’s a coding assistant or a conversational chatbot.
The Evolution of the Value Chain
Looking at the map of the AI landscape, we can see a clear progression from Genesis to Commodity.
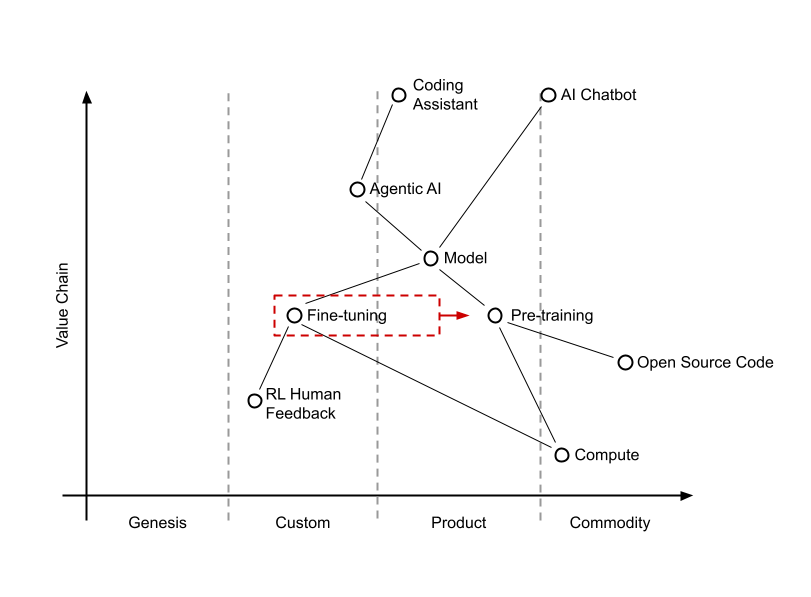
Currently, Fine-tuning and RLHF (Reinforcement Learning from Human Feedback) sit in the “Custom” and “Product” phases. While pre-training is becoming more standardized, the way a model is fine-tuned remains the “secret sauce” that determines the final product’s quality.
1. The Anthropic Move: Constitutional Automation
Anthropic has taken a unique path with Constitutional AI. Instead of relying solely on slow, manual human feedback, they’ve specialized their fine-tuning through automation.
In the realm of coding agents, this is a massive advantage. Reinforcement Learning (RL) for code is “easier” to automate because the feedback loop is objective: Does the code compile? Does it pass the unit tests? By using their own tools to code better and faster, Anthropic creates a self-improving loop that could leave the competition struggling to keep up.
2. The Google Move: Fine-Tuning at Global Scale
While Anthropic scales through clever automation, Google scales through sheer Infrastructure. By integrating Gemini into Google Search, they’ve turned their entire user base into a global fine-tuning engine.
This move is only possible because of their hardware advantage. Google’s TPU (Tensor Processing Units) are built specifically for inference at scale, making it significantly cheaper for them to process these billions of interactions compared to competitors relying on general-purpose GPUs.
3. The OpenAI & Copilot Legacy
OpenAI was the first to prove that clever fine-tuning could capitalize on pre-trained knowledge, giving us ChatGPT. GitHub Copilot did the same for code completion. They moved the needle by finding a way to actually use the concepts the models had learned.
However, the “new” players are now perfecting this art, squeezing even more power out of the same pre-trained foundations.
Key Takeaway: Fine-tuning is what unleashes the power of pre-training. You can feed a model more data to teach it new concepts, but without a sophisticated fine-tuning layer, that knowledge remains trapped.
What’s Next? The Return to Data
Software moves in cycles. As fine-tuning techniques eventually move from “Custom” to “Product” and become more accessible, the battle will inevitably shift back to the Pre-training phase and the data that fuels it.
The big question remains: Will GitHub (and by extension, Microsoft/Copilot) be able to capitalize on the massive mountain of “free” data they sit on to dominate the next pre-training cycle?

